|
Articles
THE COMPUTABLE CITY
Paper By
Michael Batty
Centre for Advanced Spatial Analysis,
University College London, WC1E 6BT, UK
ABSTRACT
By the year 2050, everything around us will be some form of computer.
Already, we are seeing a massive convergence of communications and
computers through various forms of media. Computerized highways are
in prospect and smart buildings are almost upon us. As planners we
are accus-tomed to using computers to advance our science and art
but it would appear that the city itself is turning into a constellation
of computers. The implications of this for city planning are enormous.
New data sources emerging in real time, and software to understand
many elements of the working of cities such as simulation games and
GIS are now widespread. The juxtaposition of media that a generation
ago we would have been regarded as unthinkable is generating entirely
new opportunities for understanding and planning cities. This paper
raises these issues through a travelogue across the Internet. Ideas
for what is becoming possible in our domain are illustrated from that
latest of networking triumphs, the World Wide Web, from which we draw
examples of cities in situ, in vitrio, in the abstract, in real time,
and in cyberspace.
A CONTINUING REVOLUTION
This past Christmas, my wife bought a mid-range Macintosh computer
from a supermarket in England for word-processing. The model on offer
contained a digital television tuner and a CD player which we thought
might be useful especially as I envisaged that I might learn how to
make QuickTime movies if I could snatch a bit of spare time. When
we got the machine home and switched it on, we experimented with the
multimedia and soon discovered that not only could you record as much
TV as your hard disc could contain, play it back, edit it, but you
could freeze frames and immediately print them, you could load them
into drawing packages and you could cannibalize them for other purposes.
Even more remarkable was the fact that the tuner was also able to
access the two passive information systems which have been available
for almost 15 years in Britain - Ceefax and Oracle which the BBC and
ITV channels run respectively. Our regular TV in the corner of the
room could do none of these things and thus quite unwittingly we were
already in possession of the ultimate electronic box which represents
the convergence of the computer, the television, the fax and every
other electronic media which the pundits are still telling us will
only happen by the end of the century !
Three years ago at Sun Microsystems in Mountain View I had seen workstations
with TV windows running alongside other software but I had not expected
to see them so soon on a low-cost Macintosh. You cannot yet buy one
of these machines in the United States and despite my best efforts,
I cannot find out why. I suspect it is something to do with the way
television is regulated in each country for it clear that the technology
is there and in fact has been for some time. In Berkeley recently,
Pravin Varaiya who is the Director of the PATH program which is developing
automated highways, also told me that they had attached a couple of
cheap still cameras to their Macintoshes and that software was now
available on the Internet which enabled them to turn their machines
into videophones. In short, it is possible to have real time video
hookups on the Internet across the world essentially providing free
voice and video mail. TV, fax, videophone, computer all in one, forming
the ultimate communications device.
What is so remarkable about all these events and many others which
are besieging us daily is not that they are technologically surprising
but that the speed at which they are being developed is so astonishing
(Negroponte, 1995). Computers, after all, as the pioneers such as
Turing, von Neumann and others told us 50 years ago, are universal
machines, but we still find this hard to absorb. Technologies which
lead to sweeping changes within society usually result from innovations
whose impact is largely unforeseen at the time of their creation (Hapgood,
1993). Computers provide the very best example of this phenomenon.
In the immediate aftermath of their simultaneous invention in a number
of places during World War 2, the conventional view amongst the industry's
founders was that no more than a handful would ever be required, and
these would be used solely for scientific purposes. 30 years later
just prior to the development of the personal computer, IBM, Hewlett
Packard and DEC - the leaders of the mainframe and minicomputer industries
- all went on record as doubting that the microprocessor could ever
become the basis for devices as ubiquitous as the television and the
telephone. This was less than 20 years ago.
The history of computing is full of such examples. Even the greatest
visionaries such as von Neumann (Macrae, 1992) who predicted that
computers would revolutionize science, and Vannevar Bush (1945) who
foresaw the development of multimedia, failed to see the profound
impact these technologies would have on material production as well
as social behavior. Not only was the path to miniaturization barely
foreseen, but perhaps more important, the convergence of computers
and telecommunica- tions which now represents the cutting edge of
the revolution, was largely unanticipated. At present, there is much
speculation that interactive television, multimedia, and networking
will change behavior in ways we cannot envisage, yet the really radical
notion that all our material infrastruc- ture from communications
to shelter is turning into computers still seems far fetched. But
within 50 years, everything around us will be some form of computer
and the ways we will access this and use it to interact with each
other will be through software. By the mid-twenty-first century, cars
will be computers, buildings will be computers, entire cities will
be computers, all wreaking profound changes on the form and functioning
of our environ- ment and the ways we will seek to understand and change
it. The interaction of computers across networks reflected in SunŐs
slogan ŇThe computer is the network, the network is the computerÓ,
is not simply leading to an order of magnitude change in computer
power, as if that is not enough. It is leading to a deep qualitative
change in what computers are being used for. The telephone and the
television provided new media for active and passive interaction but
the computer is generating a qualitative change in computational interaction
which is considerably more powerful than any interactive media developed
so far. The dominant paradigm for this is, of course, the network
(Kelly, 1994) which is enabling many new functions and forms of behavior
to be developed. Apart from the obvious possibilities of remote computing,
access to information services such as data, libraries, software for
computing, text processing and design etc. over the net is enabling
entirely new ways of working as well as new forms of work. Such opportunities
generate different forms of interaction which both substitute for
and complement one another in a myriad of unanticipated ways, thus
leading to new forms of social behavior. This, in effect, is but one
of many indicators that social structure and behavior is becoming
ever more complex, with important implications for our understanding
and planning of cities and regions.
This conference is mainly about the uses of computers in understanding
and planning cities, and until quite recently, this was the predominant
role for computers in planning. But it is increasingly clear that
computers are now changing the very systems that we are seeking to
understand using the same computers, and this in itself is generating
important consequences for how we use computers in planning, consequences
which have barely been raised to date. We will explore this conundrum
here, suggesting that it is important to examine the ways in which
computers are changing the methods for understanding as well as changing
the structure and dynamics of the city itself. This is the phenomenon
that we will refer to as The Computable City. In the past, the ways
we have used computers to understand and help in planning the future
city have been quite different from our concern for how computers
and information technologies change the city, but with the recent
proliferation of local and global information networks, these two
domains have begun to collide and coincide. This is best seen in the
fact that computer hardware and networks as well as software used
traditionally to understand the city by professional researchers and
planners are now being used by a variety of interests and agents whose
concern is somewhat different, involving the very actions and behavior
that we are usually see as composing the fabric and structures to
be understood and planned for. Of course, this coincidence of those
planning and those planned for is hardly new. Social scientists have,
for long, pondered the intersection of interests between planners
and the planned, and the degree to which an appropriate understanding
of urban behavior can be seen in terms of one domain rather than the
other. But in the context of computation and particularly the use
of networks and computers, this difference and coincidence takes on
a new significance which we will begin, albeit in a rather preliminary
and somewhat cavalier way, to discuss here.
In the rest of this paper, we will first outline a simple framework
for reconciling our knowledge about how we use computers to begin
to plan for cities that are composed of these very same machines.
The network paradigm that is emerging is helpful to us here and we
will illustrate several examples of the ways in which computation
is changing our perceptions of the city using the latest Internet
fashion of the moment, the World Wide Web (WWW), to present our thoughts.
We explore how we can use computers to watch real cities, how we can
simulate abstractions of cities, how we can use computers to learn
about cities, and how we can live and work within virtual cities.
Our examples simply give us a glimpse of the kind of computable city
which is emerging, one which is changing daily and which will have
changed substantially by the time this paper is formally presented.
COMPUTERS FOR PLANNING : PLANNING FOR COMPUTERS
Most of our applications of computers for understanding and planning
cities have been for purposes of analysis, modeling and design, for
storing data, and perhaps more recently for communicating data and
ideas. Only very recently has the notion that computers might be more
than simply a means for a better understanding and that computation
might be more than simply scientific analysis become significant.
Over 30 years ago, Meier (1962) speculated upon the notion of the
city as a formal mechanism for communi- cations and there has been
a stream of work on the new geography of high technology production
and services (Castells, 1989) but in a sense, this has remained very
separate from the use of computers within the planning process. Different
ideologies and interests pertain to these two domains and so far,
their study has had little in common.
It is the synthesis of computers and telecommunications which threatens
to change all this. The emergence of computer networks which are able
to monitor systems in real time while simultaneously allowing analysis
of those same systems is something which is very new, at least on
a wide- spread scale. The increasing convergence of the non-routine
and the routine in the same set of technologies is making possible
the study and analysis of systems in a way that was not possible hitherto.
Furthermore, the fact that so much routine behavior which has an impact
on the city is now being ÔinfluencedŐ by electronic networks is changing
the very phenomena which planners and spatial analysts have traditionally
studied. It is a cliche to say that computers and telecommunications
are annihilating distance as much they are changing time but there
are substantial changes underway which will probably change the very
notion of the city which we have grown up with. Moreover, what is
going to be very clear in the future is that to study cities in any
manner, it will be necessary to use diverse methods of computation
which will vary from the straightforward browsing of digital data
to much more sophisticated methods of simulating futures. To plan
those same cities, we will have to complement our set of planning
tools with those that involve the design, operation, and selection
of different types of networks and information.
This is a complex prospect and we need some way of making sense of
it all. First let us make a distinction between the material and nonmaterial
worlds which in terms of cities we may think of as infrastructure
and the way populations behave within that infrastructure respectively.
The study and planning of cities has always approached this distinction
with respect to how human behavior influences physical form and space
although these limits have been the subject of intense debate in the
last 30 years. Part of human behavior is our quest to understand and
plan the city although many have argued that this activity must be
treated no differently from any other type of behavior which affects
the city. Nevertheless, a distinction must be made, otherwise there
would be no distinct professional activity or concern. When computers
were first invented 50 years ago, they gradually en- croached upon
these professional concerns and by the 1960s had become significant
enough to constitute a separate field of inquiry, notwithstanding
the controversies such approaches implied. But only recently have
computers through networks begun to dramatically affect both the infrastructure
of the city as well as those other forms of behavior which planners
and urban analysts view as determining spatial and social structures.
In short, computers which were once thought of as solely being instruments
for a better understanding, for science, are rapidly becoming part
of the infrastructure itself, controlling new infrastructure through
their software, influencing the use of that infrastructure, and thus
affecting space and location. In one view, the line between computers
being used to aid our understanding of cities and their being used
to operate and control cities has not only become blurred but has
virtually dissolved. In another sense, computers are becoming increasingly
important everywhere and the asymmetry posed by their exclusive use
for analysis and design in the past and their all pervasive influence
in the city is now disappearing. In both cases, the implication is
that computers will have to be used to understand cities which are
built of computers.There will be no other way.
It is easy to make too much of these events. For some, cities will
never be perceived as being formed from computers and networks, and
of course, ours is only a partial view. For a long time to come, the
line between computers in cities and everything else will be a clear
one and it will be necessary to extend our understanding across this
line. In fact, this means that our understanding of cities and their
planning is more complex than ever it was a generation of more ago,
for now we need to consider new forms of network as well as the traditional
ones based on material physical infrastructures. Besides adding to
complexity through increased opportuni- ties for interaction and new
forms of organization, cities are becoming increasingly invisible
to study and analysis in traditional ways as more and more electronic
media appear. As we will argue later, it is very likely that the degree
of complexity will soon overwhelm traditional approaches to social
control and this is already seen in the massive decentralization which
computers are hastening (Kelly, 1994; Resnick, 1994).
In this paper, the lens through which we are viewing the city is
the computer and we will direct all subsequent discussion this way.
We will, in fact, make a distinction between real cities as viewed
using computers and abstract cities as simulated on computers. By
real cities, we mean those elements of cities which we might study
using computers which detect and control elements such as transportation
networks, utilities, remote sensors, and other data. In contrast,
the study of abstract cities involves the use of computers for analysis
and modeling, removed somewhat from the routine and nonroutine functioning
of cities in which control is the modus operandi. Between these two
poles lies the use of computers for interacting within cities, for
buying and selling, for leisure, for work and for a host of activities
that were previously carried out without computers. This is the virtual
city, it is cyberspace, the world of email, the net, and such like.
Connected to this, is the world of structured learning which in terms
of our understanding of cities involves the real, the abstract and
the virtual in diverse combinations.
Our perspective is hardly well-formed, nor is it comprehensive but
our purpose here is to raise questions and illustrate examples of
what is happening. To this end, we will discuss these different views
of the computable city in terms of how we might use computers to watch
real cities using online data, to simulate abstractions of cities
perhaps using the same online data, to learn about cities using both
these media, and lastly to explore the new world of the virtual city
in which traditional forms of interaction are being both substituted
for and complemented by the new media.
WATCHING REAL CITIES
From the beginning in the 1950s, computers have been used to store
and process data of use to city planners. Before the dawn of the digital
computer, as far back as Herman Hollerith, computational devices were
used for such data. Indeed, the original momentum for widespread digital
computation came from the development of information systems for transactions
processing. Although most digital data for cities until quite recently
has been available for nonroutine functions such as that collected
by the population censuses, routine data is now becoming available.
Real time data from industrial concerns has been available for a while
as has financial data but now data pertaining to functions relevant
to physical and spatial problems is online. Satellite data is routinely
available at the global level over the Internet as illustrated by
the numerous online weather reports but the most significant types
of data pertain to traffic and movement. Real time traffic volumes
and speeds, levels of congestion and accident hot spots are available
at an increasing number of sites if one has the technology to access
this, thus making possible analysis which is close to real time. Three
examples which have appeared on the WWW within the last 6 months make
the point.
Our first is available from the California Department of Transportation
- CALTRANS - and associated sites involved in monitoring traffic in
the State. Real time reporting of traffic speed and volumes in tabular
or map form are available for a cluster of cities. We illustrate the
case of San
Diego in Figure 1 (http://www.scubed.com:8001/caltrans/sd/big_map.shtml)where
we show traffic volumes on the main highways which change every five
minutes as new data is fed across the net to the Web. The data is
probably still only of novelty value and it is unlikely that much
real time analysis can yet be done with this. But the fact that it
is possible at all and that it is in the public domain is likely to
change routine decision- making concerning trips while enabling longer
term nonroutine analysis of congestion and capacity. Of course, with
the development of navigational instrumentation in automobiles, this
kind of data might be immediately useful and in time it is this which
will be routinely available for all major highways and for all vehicles
which can make use of it. Business and government, of course, have
long used such data but this does begin to reveal that the problem
will be how to use the data. The problem is no longer whether the
data can be collected or exists but how to act on it. As with most
remotely sensed data, the volumes are so great that most of it is
lost and there is an urgent task to develop analytical software which
can use it to best purpose.
Our second example is more obvious but equally innovative. The Lawrence
Berkeley Lab at the University of California have the entire 1990
US Census of Population online. It is possible for any user in the
world who has access to an Internet account (and the cost for connection
can be as low as $3 per week for a commercial service !) to download
any element from this data set to a remote machine at a variety of
spatial scales from the block group up to the entire USA. Reportedly,
the LBL will do the same for the 1980, 1970 and 1960 Censuses in the
near future, thus providing a remarkable resource which throws into
confusion much of the debate about data costing and value added. However,
the problem is not simply one of data volumes but of interpretation.
Software is required and this means some form of GIS or nonspatial
information system which can enable the data to be viewed either visually
or numerically. Figure
2 (http://cedr.lbl.gov/cdrom/lookup/)shows the typical layout
for this home page which outlines the service for 1990 data. Downloading
can be slow especially at peak times on the information highway. The
US Bureau of the Census and the US Geological Service (USGS) also
have services which enable spatial data such as TIGER files, land
use cover and digital terrain models to be downloaded for many areas
within the US.
Our last example pertaining to data involves a network of pointers
called GeoWeb which acts as a user-friendly guide to geographical
data which is online. Devised by Brandon Plewe (1995) at SUNY-Buffalo
as a pilot model for building spatial data infrastructure, it enables
one to browse through a veritable treasure trove of spatial data available
over the Internet. It is in fact more a resource to learn about what
data is available and what software can be used in its access and
analysis rather than a means for downloading the raw material. The
home page is shown in Figure
3 (http://wings.buffalo.edu/geoweb/). As such, GeoWeb is an excellent
illustration of the way the World Wide Web (which is a subset of resources
available over the Internet) can be accessed and searched. The screens
shown here are from the browser called Mosaic which enables different
documents to be accessed using hypertext - hotlinks which point to
other documents which summarize resources at different locations on
the Web. By clicking on these hotlinks, the searcher moves across
the net to the physical location of the document and resource, thus
building up a web of interactions. This, of course, is the way the
net can be explored but it also the way new webs can built across
the net. The pointers soon explode as Figure 4, which is a map of
four layers within GeoWeb
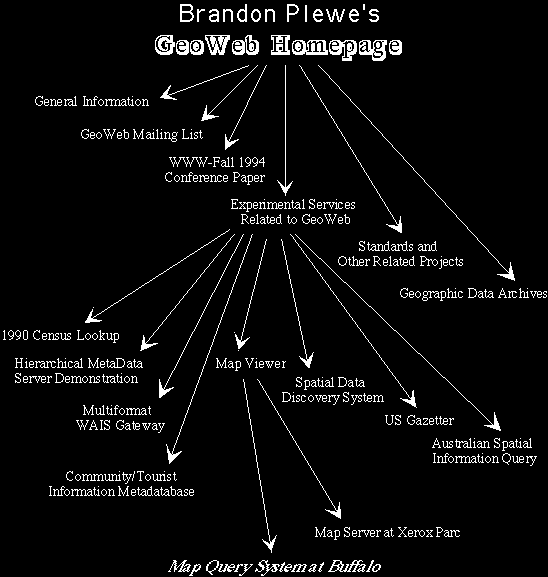
implies. This is the kind of complexity that is characteristic of
the information society and which makes traditional responses to its
study quite inadequate.
SIMULATING ABSTRACTIONS OF CITIES
The traditional use of computers in planning has been for analysis
and forecasting from a data or a modeling perspective. All we can
do here is to point to the kind of abstractions that are being developed
as computation creeps out into society at large. The broad domain
of knowledge in this area is encompassed by many of the papers at
this meeting but the emergence of networking and online data resources
is changing the field dramatically. Evidence of this comes from the
use of serious computer games such as SimCity. Reportedly, SimCity
was the most popular-selling computer game in the UK last Christmas
(Macmillan, 1995), with many more people being exposed to the game
than there are professionals concerned with the study and planning
of cities. This contrast is even starker in that straw poles reveal
that a majority of professionals in this area have never even heard
of the game. The implications for who understands cities best and
who should be involved in their planning are dramatic.
On the net, some interesting modeling applications are emerging.
There are countless GIS tutorials but descriptive simulations, some
with a Ňhands-onÓ feel, are becoming available. We will examine two.
First at USGS at NASA Ames in Silicon Valley, a group led by Len Gaydos
have put together a simulation of urban growth in the San Francisco
Bay Area as part of a wider project dealing with the human consequences
of land use change. Urban development in the Bay Area from 1820 has
been morphed together from old maps and since 1972 from satellite
imagery. Some stills from this development are shown in Figure 5 (http://128.102.124.15/usgs/HILTStart/)
but the real excitement begins when you click on the pointer beneath
these maps which starts the mpeg movie player generating an animation
of urban growth in the Bay Area. From this document, you can extract
the data for this simulation and also explore a simple model of this
growth developed by Keith Clarke and Lee de Cola based on cellular
automata (CA) (Kirtland et al., 1994). As yet, you cannot run this
model online but there are several documents on the Web where users
who log on from remote locations can run applications if the software
is mounted on their own machines. You can access Shane Murnion's ARC/INFO
tutorial(http://www.geog.buffalo.edu/) which tells you how to
construct an application and echo the results on the Web if you have
the software online. By the time I present this paper at the meeting,
we hope to have a similar simulation of the Buffalo region up and
running which we are constructing in Imagine and ARC/INFO as a prelude
to the application of various fractal and CA models of urban growth
(Batty and Longley, 1994; Batty and Xie, 1994).
Our second example is also taken from urban morphology although the
analysis contained therein is rather different. Bill Hillier and his
group at University College London have been applying ideas of space
syntax to urban form for a decade or more, as initially illustrated
in Hillier and Hanson (1984). These are models of urban structure
in which space is explored which exists between buildings rather than
within them. In a sense, the analysis seeks to interpret how space
is formed by examining the external rather than internal disposition
of functions and the way the space is configured in terms of its use.
They have developed many applications for many cities and some of
these are illustrated in their WWW server whose home page is presented
in Figure 6 (http://doric.bart.ucl.ac.uk/index.html).
Perhaps the most useful aspect of their pages so far is the easy-to-use
tutorial concerning space syntax which they are developing and which
provides a clear analysis of the modeling techniques in use.
Space syntax of this kind requires very elaborate radial route networks
of cities, usually coded according to criterion associated with the
definition of exterior space. The nearest thing to a world wide resource
containing this type of data is the line feature data called the TIGER
files which enable the geometry of the entire US to be reconstructed
at Census block level. If you go into GeoWeb and point your way to
the Census TIGER server (http://www.census.gov/tiger/tiger.html/)
you will find a useful summary of these resources with some examples
of this data online. How long will it be before the kind of space
syntax analysis developed by Hillier can be linked to data in the
TIGER files ? And will this be possible across the Web ? Much will
depend on how data and software is made available and to whom but
the prospect of other users engaging in such analysis is almost upon
us. Although I cannot point to sources, I am fairly sure that some
simple GIS packages exist on the Web which can already be used to
analyze and visualize the kind of Census data which exists at LBL.
LEARNING ABOUT CITIES
In one sense, learning cuts across all of the applications we have
intro- duced, for the very activity of accessing computer networks
and exploring resources is so new that it will represent a basic learning
experience for while yet. If you log onto the Buffalo homepage, then
you will find that besides providing a catalog to the facilities,
faculty and staff at the Geography Department and the NCGIA, there
are a various resources connected to instruction. We have already
noted structured tutorials such as Bill HillierŐs space syntax and
Shane MurnionŐs ARC/INFO document, but on the Buffalo homepage, three
courses are being developed with their own homepages in which students
and faculty are thinking aloud, online, so-to- speak. We will examine
my own course which is entitled The Geography of the Information Society
and explain what we are doing. Figure 7 (http://www.geog.buffalo.edu/Geo666/)
shows the homepage. As the title suggests, the course provides a wide
ranging introduction to exactly the material of this paper - The Computable
City by any other name (and this self-referential style which dominates
this paper is in fact quite characteristicof the complexity which
we are all facing with respect to the rapid computerization of society).
The course is structured into four parts: first a review of the emergence
of postindustrial society, and the growth of information networks,
computers, software, orgware and so on; second an outline of the geography
of high tech manufacturing, services and globalization; third, the
development of information infrastructure in cities largely involving
telecommunication but also smart buildings and electronic highways;
and finally, the emergence of cyberspace and virtual communi- ties.
If you click on our homepage, you will see a logo (Figure 7), an
outline of the course, and a list of participants: myself and students
whose names when clicked reveal their own homepages on which they
can experiment with anything they like - biographical details, pointers
elsewhere revealing their preferences, papers they have written and
so on. Also presented is a course schedule which if clicked provides
a set of hierarchical pointers to papers written by each student for
particular sessions, as well as pointers to the rest of the world.
For example, in the section on technopolis and science parks, pointers
are given to places like Tsukuba science city, Blacksburg Electronic
Village, Research Triangle Park, Computer Manufacturing in Austin
TX, and so on. Finally there are pointers to what we call Neat Cyberspace,
examples of which we will give in the next section. The whole idea
of this exercise is to provide us with ways not only to present our
work to others and get feedback - you can send us email about this
from within the Web pages - but also pointers to other parts of the
Web where others have similar concerns to ours. Of course, to pretend
that this is all there is to the course is fanciful and dangerous
and there are many topic areas even within computer-oriented planning
that would not be appropriately studied through the Web. But at least,
this gives an idea of what can be done even though it is all Ňunder
constructionÓ.
Our second example is perhaps already more elaborate. Bill Mitchell
and Mitch Kapor taught a course entitled Digital Communities at MIT
last fall. Their homepage is illustrated in Figure
8 (http://alberti.mit.edu/arch/4.207/homepage.html). The design
is similar to that which we have adopted although references to literature
are more extensive and the document is more complete in that the course
has already been taught and all the student papers prepared. What
is important about these attempts is that they build on one another.
Our page points to theirs, but not theirs to ours as yet, but nevertheless,
the way the web is woven is an all important part of the learning
experience. In a way, this is the network paradigm in its purest and
most archaic form. The kind of complexity that is writ- large in these
kinds of perspectives on the Internet give some sense of how overwhelming
is the study of the information society. How to map and chart, indeed
even explore this kind of complexity is something that we have not
yet faced but of course, this is the very essence of the computable
city. Moreover, how all this interfaces with more traditional infrastructures
and behaviors as well as more traditional approaches adds other layers
to this complexity.
LIVING IN VIRTUAL CITIES
We have already glimpsed the idea of the virtual city through examples
such as GeoWeb and through our pointers to the information society.
There is much written about this kind of cyberspace and how the net
is being populated by nerds and hackers whose very existence involves
living online. But the most exciting prospect involves the emergence
of services which have traditionally been associated with non-electronic
access and in this penultimate section, we will provide a couple of
examples. But first some words about the Internet for it is important
to see this in the broader context of the network society. The Internet
has become the de facto symbol of the network society in that its
growth, once begun, has spun out of control. It has become the skeleton
for global computer-communications interaction. Although elaborate
networks proliferate in the private and public sectors, most of then
are gatewayed to the Internet where the range of services is enormous
and increasing at rates often in excess of 10 percent each month.
It is here that cyberspace is most fully developed, with an increasing
range of routine and not-so-routine functions which enable users to
shop, study, work, and play in a virtual world. In fact, the idea
of virtual reality is perhaps a little extreme a way of characterizing
cyberspace and the net for in essence, its functions simply replace
traditional modes of communication and interaction with electronic.
Two examples simply touch the edge of this virtual world. In Singapore,
at the National Computer Board, they have constructed an interface
to the net which they call Cyberville. This is simply a way of exploring
cyberspace but it is modeled on the analogy of a small town, a so-called
electronic village containing all the kinds of physical land use functions
or public/pri- vate buildings which one might associate with a well-balanced
community. This image is in essence the homepage of Cyberville, shown
in Figure 9 accessible at http://king.ncb.gov.sg/cyber/cville.html
which has become the kind of icon used in many places for accessing
and organizing entry to the Web. Click on any of the functions - stock
exchange, science centre, university, town hall, movie theatre and
so on and you move across the net to pages that display and point
you to Web sites which contain those functions. In short, Cyberville
is an intelligently organized entry point to the Web for users who
wish to focus on the sorts of services one can access electronically.
For example, if you click on the stock market, you can eventually
find yourself at MITŐs AI Lab where they have an experimental stock
market analyzer, indeed if you click on any of these items. you can
begin to travel the Web moving from site to site according to the
structure embedded into each homepage, but directed initially by Cyberville.
This is a clever way of organizing entry to such electronic spaces
and someday, all of our entry points will be so configured, at least
for the end user, if not for most others.
One last example illustrates the point again. We will not show the
homepage but if you click on this
transports you to Cyberia which is an electronic shopping mall
in Houston (no comment !). I have searched in vain in this and other
such malls for places to actually enter credit card information and
to make orders but invariably all the links are ŇdownÓ as users and
owners begin to figure out not only the economics of the Web but more
importantly its security. Once there however, on the Web, the variety
of experiences can be overwhelming and the search can be endless.
How many sites and documents there are on the Web is unknown. Plewe
(1995) estimates that six months ago, over one million documents existed
but this may be an underestimate for there are now 30 million or more
users of the Internet. Once television becomes interactive and once
video and other media can be shipped over the net on demand (for this
implies that all media will be digital, hence each copy will be almost
zero cost), the kind of complexity that we see here will be extensive.
It is then that virtual cities will intermingle with real cities,
when the abstract and the real will merge into one another, and it
is then that our traditional concepts of understanding, let alone
planning the city will simply disappear. This is a challenge that
we must begin to address if we are to simply cope with these changes.
THE FUTURE
This meeting will be largely concerned with the use of new methods
of analysis, modeling and design which are informed by computers rather
than the broader kinds of activities which we have alluded to here.
But there is an urgent need to generalize our debate in the light
of the way cities themselves are changing, the way activities are
decentralizing in both time and space and the way new network forms
are dispersing and concentrating spatial activities in very different
ways from the past. Those who work with computation are well placed
to make important contributions to this broader debate for the use
of new forms of computer and network, new digital data sources, and
new software across the net in itself represents the way the city
is changing. New insights will only come if new forms of computation
are developed, requiring all who study the city to become immersed
in its intrinsic computability.
REFERENCES
Batty, M. and Longley, P. (1994) Fractal Cities:
A Geometry of Form and Function, Academic Press, London and San
Diego.
Batty, M., and Xie, Y. (1994) From Cells to Cities, Environment and
Planning B, 21, s31-s48
Bush, V. (1945) As We May Think, Atlantic Monthly, 176, 101-108.
Castells, M. (1989) The Informational City, Blackwells, Oxford, UK.
Hapgood, F. (1993) Up the Infinite Corridor: MIT and the Technical
Imagination, Addison-Wesley, Reading, MA.
Hillier, B., and Hanson, J. (1984) The Social Logic of Space, Cambridge
|
Editorial
Editorial
Board
Articles
Submit
Digital Urban
|
